Consider a random sample of size n from a normal distribution, X;~ N(μ, 2), suppose that o2 is unknown. Find a 90% confidence interval for uit = 19.3 and s2 = 10.24 with n = 16.
(_____, _____)
Answers
The 90% confidence interval for the population mean μ is (18.047, 20.553).
What is the 90% confidence interval for the population mean?A 90% confidence interval provides a range of values within which the true population mean is likely to fall. In this case, we have a random sample of size n = 16 from a normal distribution with unknown variance. The sample mean is 19.3, and the sample variance is 10.24.
To calculate the confidence interval, we use the t-distribution since the population variance is unknown. With a sample size of 16, the degrees of freedom is n - 1 = 15. From statistical tables or software, the critical value corresponding to a 90% confidence level and 15 degrees of freedom is approximately 1.753. The margin of error can be calculated as the product of the critical value and the standard error of the mean.
The standard error is the square root of the sample variance divided by the square root of the sample size, which yields approximately 0.806. Thus, the margin of error is 1.753 * 0.806 = 1.411. The lower bound of the confidence interval is the sample mean minus the margin of error, while the upper bound is the sample mean plus the margin of error. Therefore, the 90% confidence interval for the population mean μ is (19.3 - 1.411, 19.3 + 1.411), which simplifies to (18.047, 20.553).
Learn more about Confidence intervals
brainly.com/question/32546207
#SPJ11
Related Questions
please help me I have to submit it tomorrow and please while sending solution write it and send a pic please because I don't understand when someone explains it in the answer

Answers
Answer:
A
Step-by-step explanation:
I think
If the N's are placed first, how many ways are there to choose positions for them?
Answers
If the N's are placed first, there are 100 word positions to choose from. To determine the number of ways to place the N's, we must consider how many N's there are. Let's assume there are 'x' N's to be placed.
For the first N, there are 100 positions to choose from. Once the first N is placed, there are 99 positions left for the second N, and so on. The total number of ways to place the N's can be calculated using the permutation formula:
P(n,r) = n! / (n-r)!
This will give you the number of ways to choose positions for the N's when they are placed first in the 100-word sequence.
If the N's are placed first, then we need to find out how many ways we can choose positions for them. Since we don't know how many N's there are, let's assume there are k N's.
In that case, we have k positions to fill with N's. We can choose any one of these positions to place the first N, then any one of the remaining k-1 positions to place the second N, and so on until we've placed all k N's.
So the total number of ways to choose positions for the N's is:
k * (k-1) * (k-2) * ... * 2 * 1
which can be written as k!.
Therefore, if the N's are placed first, there are k! ways to choose positions for them.
Note that if we know the total number of positions (say, n), then we can also calculate the number of ways to choose positions for the remaining letters (which are not N's) by using the formula (n-k)!, since we have (n-k) positions to fill with non-N letters.
To know more about permutation visit:
https://brainly.com/question/29990226
#SPJ11
The area of a circle is 18.1 km^2. Find the radius of the circle in kilometers
rounded to the nearest tenth. Use 3.14 for PI, and enter the number only.
Answers
Answer:2.4
Step-by-step explanation:
area = pi* r^2
18.1 /3.14=r^2
5.76 =r^2
Now root square
Answer:
2.4 km
Step-by-step explanation:
πr²=18.1 km²
18.1/3.14=5.76km²
576/100
24/10=2.4km
If a pet grooming salon hires an additional groomer, that worker can groom 4 additional pets per day. the average grooming fee is $25. the most the salon would be willing to pay that groomer is
Answers
The most the salon would be willing to pay that groomer is $25×4 = $100.
What is unitary method?The unitary method is a technique that determines the worth of a single unit from value of multiple units, as well as the quality of multiple units from value of a single unit.
Some key features regarding the unitary method are-
It's a method which we use for the majority of math calculations. This method will come in handy when answering questions about ratio & proportion, algebra, geometry, and other subjects.We can determine the missing value using the unitary method. For example, if one carton of juice pays $5, how much would five such packets cost? We can then easily determine the price of 5 packets, which is $25.To know more about the unitary method, here
https://brainly.com/question/23423168
#SPJ4
The graph of a quadratic equation is shown here, and the intercepts with the axes are marked. Explain how you can use the graph to write the polynomial as a product of linear factors C(x - x1)(x - x2). Be sure to state the values of x1 and x2.

Answers
The graph is a quadratic function, and the equation of the function is C(x) = (x + 4)(x - 3)
How to determine the equation of the graph?From the graph the x-intercepts are:
x = -4 and x = 3
Rewrite as:
x + 4 = 0 and x - 3 = 0
Evaluate the product of both equations
(x + 4) * (x - 3) = 0* 0
This gives
(x + 4)(x - 3) = 0
Express as a function
C(x) = (x + 4)(x - 3)
Hence, the equation of the function is C(x) = (x + 4)(x - 3)
Read more about quadratic functions at:
https://brainly.com/question/7784687
#SPJ1
Consider the O-ring Model. Suppose we have 2 types of workers: H-type (with q=0.6) and L-type (with q=0.4). If there are 6 workers, 3 of each type, based on the O-ring model, how should we allocate these workers to get the maximum output? {HLH,LHL} {HLL,LHH} {HHH,LLL} all of the above
Answers
We should allocate the workers as follows: {HLH,LHL} {HLL,LHH} {HHH,LLL} to get the maximum output.
The O-ring model states that production output depends on the quality of each worker. The quality of the final product is determined by the lowest quality worker working on the project.
In the given case, we have two types of workers: H-type and L-type.
The H-type workers have a quality of q=0.6, and the L-type workers have a quality of q=0.4.
We are to determine how to allocate the workers to get the maximum output.
The answer is all of the above.{HLH,LHL} {HLL,LHH} {HHH,LLL} is the allocation we need to get maximum output.
Here's how we arrive at the solution:
For the O-ring model, we need to group the workers in a way that minimizes the number of low-quality workers in a group.
We can have two possible groupings as follows:
{HLH,LHL} - This group has a minimum q of 0.4, which is the quality of the L-type worker in the middle of the group.
{HLL,LHH} - This group also has a minimum q of 0.4, which is the quality of the L-type worker on the left of the group.
The other grouping, {HHH,LLL}, has all low-quality workers in one group and all high-quality workers in another group. This is not ideal for the O-ring model as the low-quality workers will negatively affect the output of the high-quality workers.
Thus, to get the maximum output, we should allocate the workers as follows:
{HLH,LHL} {HLL,LHH} {HHH,LLL} all of the above
To learn more about O-ring model
https://brainly.com/question/32938866
#SPJ11
Suppose that grade point averages of undergraduate students at one university have a bell-shaped distribution with a mean of 2.61 and a standard deviation of 0.45. Using the empirical rule, what percentage of the students have grade point averages that are at least 3.96?
Answers
Approximately 0.3% of the students have grade point averages that are at least 3.96.
To determine the percentage of students who have grade point averages that are at least 3.96, we can use the empirical rule (also known as the 68-95-99.7 rule) in conjunction with the given mean and standard deviation of the distribution.
The empirical rule states that for a bell-shaped (normal) distribution:
Approximately 68% of the data falls within one standard deviation of the mean.
Approximately 95% of the data falls within two standard deviations of the mean.
Approximately 99.7% of the data falls within three standard deviations of the mean.
In this case, we want to find the percentage of students who have grade point averages greater than or equal to 3.96. To do this, we need to calculate the z-score corresponding to the GPA of 3.96, and then determine the percentage of data that falls to the right of that z-score.
The z-score formula is:
z = (x - μ) / σ
Where:
x is the value we want to find the z-score for (3.96 in this case),
μ is the mean (2.61),
σ is the standard deviation (0.45).
Calculating the z-score for 3.96:
z = (3.96 - 2.61) / 0.45 ≈ 2.99
Now, let's interpret the z-score:
A z-score of 2.99 indicates that the GPA of 3.96 is approximately 2.99 standard deviations above the mean.
Using the empirical rule, we know that approximately 99.7% of the data falls within three standard deviations of the mean. Since 3.96 is more than three standard deviations above the mean, the percentage of students with GPAs at least 3.96 can be estimated as the percentage of data beyond three standard deviations.
Considering the right tail of the distribution, we can estimate the percentage using the complement of the percentage within three standard deviations. Thus, the percentage of students with GPAs at least 3.96 is approximately:
100% - 99.7% = 0.3%
for such more question on percentage
https://brainly.com/question/24877689
#SPJ8
The percentage of students with grade point averages that are at least 3.96 is approximately 0.3%.
Give that:
The value o 3.96,
The mean: μ = 2.61,
Standard deviation: σ = 0.45.
To use the empirical rule, to assume that the grade point averages follow a normal distribution.
The empirical rule, also known as the 68-95-99.7 rule, provides approximate percentages of data within certain standard deviations from the mean in a normal distribution.
According to the empirical rule:
Approximately 68% of the data falls within one standard deviation of the mean.
Approximately 95% of the data falls within two standard deviations of the mean.
Approximately 99.7% of the data falls within three standard deviations of the mean.
To find the percentage of students with grade point averages that are at least 3.96, which means to find the percentage of data that falls above this value.
Step 1: Calculate the z-score for 3.96:
Z = (X - μ) / σ
Z = (3.96 - 2.61) / 0.45 ≈ 2.98
Step 2: Find the percentage of data that falls beyond this z-score. Since we are looking for values greater than 3.96, we look at the percentage beyond 2.98 (which is approximately three standard deviations above the mean).
According to the empirical rule, approximately 99.7% of the data falls within three standard deviations of the mean. This means that approximately 100% - 99.7% = 0.3% of the data falls beyond three standard deviations from the mean.
So, the percentage of students with grade point averages that are at least 3.96 is approximately 0.3%.
Learn more about Empirical rule here:
https://brainly.com/question/30573266
#SPJ4
true/false: the this pointer is automatically passed to static member functions of a class.
Answers
The given statement "The this pointer is not automatically passed to static member functions of a class." is false as static member functions can be called without creating an object of the class, and the "this" pointer is used to refer to the current instance of the class. Since no instance is required for static member functions, the "this" pointer is not applicable in this case.
In object-oriented programming, a class is a blueprint for creating objects, and member functions are functions defined within a class that can be called on objects of that class.
Static member functions, also known as class methods, are special member functions that are associated with the class itself rather than any specific object or instance of the class. They are declared using the "static" keyword.
Since static member functions do not operate on specific instances of the class, they do not have access to the "this" pointer. The "this" pointer is a hidden pointer that points to the current object instance, allowing non-static member functions to access the data members and other member functions of the object. However, static member functions do not have this pointer because they are not tied to any specific object.
Static member functions can only access static members of the class, which include static variables and other static member functions. They can be called using the class name itself, without creating an instance of the class. This is because they are not associated with any particular object but rather with the class as a whole.
To learn more about static member function: https://brainly.com/question/31563511
#SPJ11
What is the X-intercept for the following equation

Answers
The x-intercept of the equation 70x - 12y = 350 is (5, 0).
How to find x-intercept of an equation?The x-intercept of an equation is where a line crosses the x-axis. The x-intercept of an equation is the value of x when y equals to zero.
Therefore, let's find the x-intercept of the equation as follows:
70x - 12y = 350
Hence,
12y = 70x - 350
Let's substitute y = 0 in the equation
12(0) = 70x - 350
70x = 350
divide both sides by 70
x = 350 / 70
x = 5
Therefore, the x-intercept is (5, 0)
learn more on x-intercept here: https://brainly.com/question/14180189
#SPJ1
Nadine conducted an experiment with four possible outcomes. Trevor conducted the same experiment, but he doubled the number of trials. Which statements are true? Select two options. Trevor has more experimental outcomes than Nadine. Trevor’s sample space is greater than Nadine’s. Trevor’s experimental probability is more likely closer to the theoretical probability than Nadine’s. Nadine’s experimental probability is more likely closer to the theoretical probability than Trevor’s. Nadine has more experimental outcomes than Trevor.
Answers
Answer:
A and C
Step-by-step explanation:
Nadine and Trevor both conducted an experiment but Nadine conducted with four possible outcomes and Trevor doubled the trials, therefore, Trevor will have more experimental outcomes than Nadine because he doubled the trials. Moreover, Trevor's experimental probability is more likely closer to theoretical probability than Nadine's, therefore option 'A' and 'C' are correct.
Answer:
Trevor has more experimental outcomes than Nadine.
Trevor’s experimental probability is more likely closer to the theoretical probability than Nadine’s.
Step-by-step explanation:
Consider the regression equation:
ri - rf = g0 + g1b1 + g2s2(ei) + eit
where:
ri - rf = the average difference between the monthly return on stock i and the monthly risk-free rate
bi = the beta of stock i
s2(ei) = a measure of the nonsystematic variance of the stock i
If you estimated this regression equation and the CAPM was valid, you would expect the estimated coefficient, g0, has to be
Answers
If the CAPM (Capital Asset Pricing Model) is valid, we would expect the estimated coefficient, g0, to be zero.
In the CAPM, the excess return of a stock (ri - rf) is modeled as a linear function of the stock's beta (bi), representing the systematic risk, and the nonsystematic variance (s2(ei)). The constant term in the regression equation, g0, represents the expected excess return when the beta and nonsystematic variance are both zero.
According to the CAPM, the expected excess return for a stock with zero systematic risk (beta) and zero nonsystematic variance should be equal to the risk-free rate (rf). Therefore, in the regression equation, the expected value of g0 would be zero.
So, if the CAPM is valid and the regression equation is estimated correctly, we would expect the estimated coefficient, g0, to be close to zero.
In practice, the estimated coefficient g0 is often found to be significantly different from the market risk premium. This is because the CAPM is a simplified model of the capital markets. It ignores factors such as investor risk aversion and transaction costs. As a result, the estimated coefficient g0 should be interpreted with caution.
Learn more about the CAPM and regression analysis here:
https://brainly.com/question/31431945
#SPJ11
another financial analyst, who also works for the online trading platform, claims their clients have a lower proportion of stock portfolios that contain high-risk stocks. this financial analyst would like to carry out a hypothesis test and test the claim that the proportion of stock portfolios that contain high-risk stocks is lower than 0.10. why is their hypothesis test left-tailed?
Answers
The hypothesis test is left-tailed because the financial analyst wants to test if the proportion of stock portfolios containing high-risk stocks is lower than 0.10.
In other words, they are interested in determining if the proportion is significantly less than the specified value of 0.10. A left-tailed hypothesis test is used when the alternative hypothesis suggests that the parameter of interest is smaller than the hypothesized value. In this case, the alternative hypothesis would be that the proportion of stock portfolios with high-risk stocks is less than 0.10.
By conducting a left-tailed test, the financial analyst is trying to gather evidence to support their claim that their clients have a lower proportion of high-risk stock portfolios. They want to determine if the observed data provides sufficient evidence to conclude that the true proportion is indeed less than 0.10, which would support their claim of a lower proportion of high-risk stocks.
Therefore, a left-tailed hypothesis test is appropriate in this scenario.
Learn more about financial here
https://brainly.com/question/31299651
#SPJ11
g use green's theorem to evaluate the line integral along the given positively oriented curve f c x 2y^3 2x^2 y c consists of the arc of the curve y
Answers
To evaluate the line integral using Green's theorem, we need to express the given curve C as a closed curve and find the vector field F = (P, Q) associated with the line integral.
Let's assume the curve C consists of the arc of the curve y = \(x^2\) from (0, 0) to (1, 1) and the line segment from (1, 1) to (0, 0).
First, we express the vector field F = (P, Q) associated with the line integral:
P = \(x^2y\)
Q = \(2x^2y^3\)
Next, we compute the partial derivatives of P and Q with respect to x and y:
∂P/∂x = 2xy
∂Q/∂y = \(6x^2y^2\)
Then, applying Green's theorem, the line integral is equal to the double integral of (∂Q/∂x - ∂P/∂y) over the region R enclosed by the curve C:
∮C Pdx + Qdy = ∬R (∂Q/∂x - ∂P/∂y) dA
Since the curve C consists of a simple closed curve, we can evaluate the line integral using the double integral over the region R.
However, since the region R is not provided, it is not possible to determine the exact value of the line integral without additional information about the region enclosed by the curve C.
Learn more about green's theorem here:
https://brainly.com/question/23265902
#SPJ11
Yo Who all be living in colorado and hating the online school stuff
Answers
Answer: im livin in iowa and it sucks
Step-by-step explanation:
A rectangle measures 7.08cm by 3.2cm what is the area of the rectangle
Answers
Answer:
Measurements= 7.08/3.2
Area of rectangle= 7.08cm×3.2cm
= 22.656 cm(square)
A researcher has conducted a survey using a simple random sample of 225 elementary teachers to create a confidence interval to estimate the proportion of elementary teachers favoring the addition of a soda machine to the cafeteria. Assume that the sample proportion does not change. The researcher now decides to survey a random sample of 25 teachers instead of 225 elementary teachers. Which of the following statements best describes how the confidence interval is affected by this change? The width of the new interval is about the same width as the original interval. The width of the new interval is about twice the width of the original interval. The width of the new interval is about one half the width of the original interval. The width of the new interval is about one third the width of the original interval. The width of the new interval is about three times the width of the original interval.
Answers
The width of the new interval is about three times the width of the original interval. As the sample size decreases, the standard error of the estimate increases, resulting in a wider confidence interval. In fact, the width of a confidence interval is inversely proportional to the square root of the sample size.
The width of a confidence interval is affected by three factors: the sample size, the level of confidence, and the variability of the data. In this case, the sample size has decreased from 225 to 25, while the level of confidence and the variability of the data have remained constant.
As the sample size decreases, the standard error of the estimate increases, resulting in a wider confidence interval. In fact, the width of a confidence interval is inversely proportional to the square root of the sample size.
To be more specific, the formula for the width of a confidence interval for a population proportion is:
Width = 2 × zα/2 × SE
where zα/2 is the critical value of the standard normal distribution corresponding to the desired level of confidence, SE is the standard error of the estimate, and the factor of 2 is used to account for the two-sided nature of the interval.
Assuming a 95% level of confidence and a sample proportion of 0.5, the standard error of the estimate for the original sample size of 225 is:
SE = sqrt[(0.5 × 0.5) / 225] = 0.033
The critical value of zα/2 for a 95% level of confidence is approximately 1.96. Therefore, the width of the original confidence interval is:
Width = 2 × 1.96 × 0.033 = 0.13
For a new sample size of 25, the standard error of the estimate becomes:
SE = sqrt[(0.5 × 0.5) / 25] = 0.1
Using the same critical value of zα/2, the width of the new confidence interval is:
Width = 2 × 1.96 × 0.1 = 0.39
Therefore, the width of the new interval is about three times the width of the original interval.
Learn more about square root here: brainly.com/question/29286039
#SPJ11
Solve the inequality. (If there is no solution, enter NO SOLUTION. If all real numbers are solutions, enter REALS.)

Answers
Answer:
b ≤ -200
( - ∞, -200]
Explanation:
We have to solve
\(\frac{b}{-10}\ge20\)for b.
Multiplying both sides by -10 reverses the direction of the inequality and gives
\(b\le20\times(-10)\)which simplifies to give
\(\boxed{b\le-200.}\)We plot the above on the number line.
The above plot tells us that all values of b less than or equal to -200 satisfies the inequality.
Using the interval notation, we write the interval as
\((-\infty,-200\rbrack\)Where parenthesis tells us that ∞ itself is not included in the interval, the bracket '[' tells us that -200 is included in the interval.

HELP ASAP MONEY & WAGES!

Answers
Answer: $26.70 per hour
Step-by-step explanation:
Regular hours consists of 8 hrs
Overtime hours is 12 - 8 = 4 hours
Regular pay at "x" per hour = 5(8)(x) = 40x
Overtime pay at "2x" per hour = 5(4)(2x) = 40x
Total pay = 80x
Total Pay = $2136 = 80x
\(\dfrac{\$2136}{80}=x\)
$26.70 = x
Find the values of p and q if x-1 is a common factor of f(x)=x⁴-px³ +7qx+1, and g(x)=x²-4x² + px² +qx-3,
Answers
The values of p and q if x-1 is a common factor of f(x)=x⁴-px³ +7qx+1, and g(x)=x²-4x² + px² +qx-3,are 13/2 and -1/2 respectively.
What is a factor?In Mathematics, factors are positive integers that can divide a number evenly. Suppose we multiply two numbers to get product. The number that is multiplied are the factors of the product. Each number is factor of itself. Factors have many real-life examples, such as arranging sweets in box, arranging numbers in pattern, distributing chocolates among children, etc. To find the factors of number, we need to use the multiplication or division method.
Factors are numbers that can divide a number exactly. Hence, after the division, there is no remainder left. Factors are numbers you multiply together to get the another number. Thus, factor is the divisor of another number.
f(x)=\(x^{4}-px^{3}+7qx+1\)
= 1-p+7q+1
= p-7q=2---------1
g(x)= \(-3x^{2} +px^{2} +qx-3\)
= -3+p+q-3
=p+q= 6----------2
p-7q=2
p+q=6
-----------------
By subtracting 2 from 1
-8q=4
q=-1/2
putting value of q in equation 2 we get,
p+(-1/2)=6
p=6+\(\frac{1}{2}\)
p=13/2
To know more about factor visit: https://brainly.com/question/24182713
#SPJ9
Which of the following does the Pythagorean Theorem reveal
Answers
According to the Pythagorean theorem, "in a right-angled triangle, the squares of the hypotenuse side is equivalent to the sum of squares of the other two sides," the hypotenuse side is the longest side of the triangle.
This is further explained below.
What is Pythagorean Theorem?Generally, The Pythagorean theorem is a well-known geometric theorem that states the number of squares just on the legs of a right triangle is equal to the square just on the hypotenuse (the side that is opposite the right angle).
This theorem can also be expressed in the familiar algebraic notation of a2 + b2 = c2, where a and b are the lengths of the legs of the triangle.
The Pythagorean theorem, sometimes known as Pythagoras' theorem, is an essential connection in Euclidean geometry that describes the relationships between the three sides of a right triangle.
It indicates that the total of the areas of the squares on the other two sides is equal to the area of the square whose side is the hypotenuse.
In conclusion, This means that the area of the square whose side is the hypotenuse is equal to that amount.
Read more about Pythagorean Theorem
https://brainly.com/question/14930619
#SPJ1
CQ Not found: Answered Generally
Would you please help me solve for x it should be a degrees but I’m not sure what it is
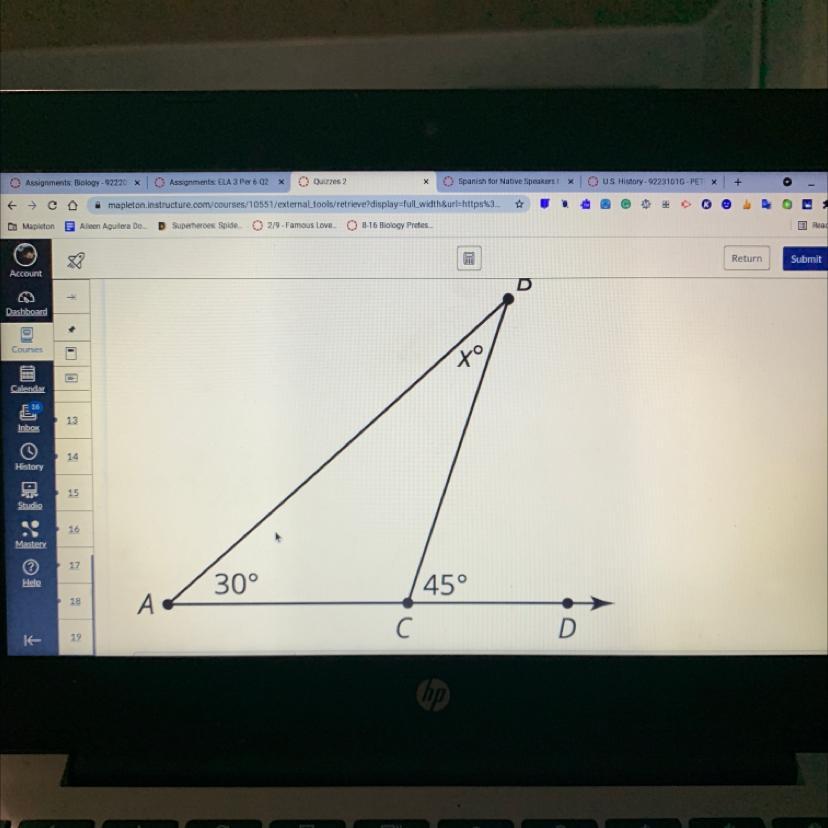
Answers
Answer:
x=15º
Step-by-step explanation:
A triangle's angles add up to 180º.
∠A=30º
∠C=180º-45º
∠B=xº
To find ∠B we have to first find ∠C.
Since ∠C does not have an angle, knowing that a straight line is 180º we can subtract it from 45º to find ∠C.
180-45=135
∠C=135º
Now add ∠A and ∠C.
30+135=165
Subtract the sum from 180º
180-165=x
x=15º
Hope this helps :)
a developmental psychologist studies the number of words that seven infants have learned at a particular age. the numbers are 10, 12, 8, 0, 3, 40, and 18. figure the (a) mean, (b) median, and (c) standard deviation for the number of words learned by these seven infants. (d) explain what you have done and what the results mean to a person who has never had a course in statistics
Answers
The mean of 13 words, median of 10 words, and standard deviation of 13.20 words give us an idea of the central tendency and variability of the number of words learned by the seven infants.
(a) Mean: The mean is the average of the values and can be calculated by adding all the values and dividing by the number of values. For the number of words learned by the seven infants, the mean can be calculated as follows:
mean = (10 + 12 + 8 + 0 + 3 + 40 + 18) / 7 = 91 / 7 = 13
So the mean number of words learned by the seven infants is 13 words.
(b) Median: The median is the middle value in a set of values. If the number of values is odd, the median is the middle value. If the number of values is even, the median is the average of the two middle values.
0, 3, 8, 10, 12, 18, 40
The median is 10 words.
(c) Standard Deviation: The standard deviation is a measure of the spread or variability of a set of values.
First, the deviations from the mean are calculated as follows:
10 - 13 = -3
12 - 13 = -1
8 - 13 = -5
0 - 13 = -13
3 - 13 = -10
40 - 13 = 27
18 - 13 = 5
Next, the squared deviations are calculated:
(-3)^2 = 9
(-1)^2 = 1
(-5)^2 = 25
(-13)^2 = 169
(-10)^2 = 100
27^2 = 729
5^2 = 25
The variance is then calculated as the average of the squared deviations, divided by the number of values (n - 1):
variance = (9 + 1 + 25 + 169 + 100 + 729 + 25) / (7 - 1) = 1058 / 6 = 176.33
Finally, the standard deviation is calculated as the square root of the variance:
standard deviation = sqrt(variance) = sqrt(176.33) = 13.20
(d) Explanation: The mean, median, and standard deviation are measures of the central tendency and variability of a set of values. The mean is the average of the values and gives an idea of the typical value.
In this case, The mean tells us that the typical number of words learned by the seven infants is 13 words, the median tells us that half of the infants learned more than 10 words and half of the infants learned less, and the standard deviation tells us that the values are spread out around the mean with a deviation of about 13 words.
To learn more about seven infants please click on below link.
https://brainly.com/question/13023503
#SPJ4
What is an equation that represents a non proportional relationship???
I really need help(I know nothing about proportional and non proportional equations)
Answers
y=mx+b
Calculate the area of the triangle? What is the best way to solve it

Answers
Answer: Find the the height and length of the triangle. I'm not sure what it would be but then use a1 + a2 to find the area
Answer:
Formula of triangle: A = 1/2 x b x h
Step-by-step explanation:
Solve the base of the triangle by solving the distance between points (-2,0) and (f, -5) in units, and then do the same for height: find distance between points (-2, 6) and (-2, 0). Once you find the distance, input value of base and height into the formula and solve to get the area!
When a number is raised to a power, is the result always larger than the original number? Support your answer with some examples.
Answers
Answer:
That actually kind of depends. If it is raised to a negative exponent, it will be a fraction of its original value. However, to answer your question, it will be a bigger number because you are basically multiplying the number by another number, x amount of times. For example, 6^3 is equal to the equation 6x6x6. Using GEMDAS, our answer is 216. Essentially, you're following the basic rules of multiplication...
I'm not if this will help. Hopefully, it does though...
Step-by-step explanation:
The result of raising a number to power can be larger or smaller than the original number depending on the value of the power.
Whether a number raised to a power is larger than the original number depends on the power that the number is raised to.
If the power is 1, then the result will be the same as the original number. For example, 5 to the power of 1 is 5.
However, if the power is greater than 1, then the result will be larger than the original number. For example, 5 to the power of 2 (written as 5²) is 25, which is larger than 5.
On the other hand, if the power is between 0 and 1, then the result will be smaller than the original number. For example, 5 to the power of 0.5 (written as √5) is approximately 2.236, which is smaller than 5.
To summarize, the result of raising a number to power can be larger or smaller than the original number depending on the value of the power.
Know more about the power here:
https://brainly.com/question/28782029
#SPJ11
the base salary of an employee and a 2% salary increase
Answers
I'm assuming the base salary of this employee is $25.00
25.00+2%
Convert the percent into a decimal.
0.02
Now multiply.
25.00x0.02=0.5
Now add to the base salary.
25.00+0.50=$25.50
The 2% increase was $0.50
The total is $25.50
nya
A number z squared, decreased by 7
Answers
9514 1404 393
Answer:
z² -7
Step-by-step explanation:
A square is indicated using an exponent of 2. "Decreased by 7" means 7 is subtracted.
z squared, decreased by 7 is ...
z² - 7
elmer has overdrawn his bank account and now has an account balance of -$35.83. The bank allows Elmer to withdraw and additional $5.76. What is his new account balance
Answers
Elmer new account balance is -41.59
How to calculate the new account balance ?
Elmer has overdrawn funds from his bank account
His account balance is -35.83
The bank allows an additional withdrawal of $5.76
Elmer's new account balance can be calculated as follows
The account balance can be calculated by subtraction 5.76 from 35.83
-35.83 - 5.76
= -41.59
Hence Elmer's new account balance is $41.59
Read more on account balance here
https://brainly.com/question/24614549
#SPJ1
Seven less than the product of a number n and
1
is no more than 95.
4.
Fill in the boxes.
In 17
95
102
n
Answers
Answer:
(n-7) ≤ 95
Step-by-step explanation:
We need to write the expression for the given statement.
Seven less than the product of a number n and 1 means (n-7).
It is no more than 95. No more than 95 means less than or equal to i.e.
(n-7) ≤ 95
Hence, the above inequality shows the given statement.
In the U.S., shoe sizes are defined differently for men and women, but in Europe, both genders use the same shoe size scale. The accompanying histograrn shows the European shoe sizes of 269 male and female college students, converted from their reported U.S. shoe sizes. a) Describe the shape. b) How many modes does the histogram have? What might explain that? Click the icon to view the histogram of shoe sizes. a) The distribution is roughly symmetric and bimodal. b) Choose the correct answer below.
Answers
a) The distribution is roughly symmetric and bimodal. b) The histogram has two modes, which may be due to the different shoe size scales used for men and women in the U.S. but not in Europe.
The histogram of European shoe sizes of 269 male and female college students converted from their reported US shoe sizes is not visible based on the information provided, but the questions are clear.
a) The shape of the distribution is not visible, but it is mentioned that it is "roughly symmetric and bimodal".
b) There are two modes in the histogram. This could be because shoe sizes in the United States are defined differently for men and women, but not in Europe. As a result, the histogram of the distribution of European shoe sizes for both men and women may show two distinct peaks.
To learn more about histogram.
https://brainly.com/question/30354484
#SPJ4