
Answers
Answer:
142 cm^2
Step-by-step explanation:
2(L*H)+2(L*W)+2(W*H)=SA
7*3=21
21*2=42
7*5=35
35*2=70
5*3=15*2=30
30+70+42=142
Related Questions
Use a formula to find the surface area of the figure. 13 in. T I ***** 11 in drawing not to scale 30 in. O 287 in. 2 858 in. O 574 in.

Answers
ANSWER:
The surface area of the figure is 574 in^2
STEP-BY-STEP EXPLANATION:
We have that the surface area of a rectangular prism is given by the following formula
\(\begin{gathered} A=2\cdot l\cdot w+2\cdot l\cdot h+2\cdot w\cdot h \\ \text{where l is the length, w is the width and h is the height} \end{gathered}\)replacing:
\(\begin{gathered} A=2\cdot11\cdot6+2\cdot11\cdot13+2\cdot6\cdot13 \\ A=132+286+156 \\ A=574 \end{gathered}\)Gas Mileage. Based on tests of the Chevrolet Cobalt, engineers have found that the miles per gallon in highway driving are normally distributed, with a mean of 32 MPG and a standard deviation of 3.5 MPG. a) What is the probability that a randomly selected Cobalt gets more than 34 MPG? b) Suppose that 10 Cobalts are randomly selected and the MPG for each car are recorded. What is the probability that the mean MPG exceeds 34 MPG? c) Suppose 20 Cobalts are randomly selected and the MPG for each car are recorded. What is the probability that the mean MPG exceeds 34 MPG?
Answers
a) the probability that a randomly selected Cobalt gets more than 34 MPG is approximately 0.7149.
b) the probability that the mean MPG exceeds 34 MPG for a sample of 10 Cobalts is approximately 0.035.
c) the probability that the mean MPG exceeds 34 MPG for a sample of 20 Cobalts is approximately 0.005.
a) To find the probability that a randomly selected Cobalt gets more than 34 MPG, we need to calculate the area under the normal distribution curve to the right of 34 MPG.
Using the z-score formula, we can convert the MPG value to a standard score (z-score) using the formula:
z = (x - μ) / σ,
where x is the given value (34 MPG), μ is the mean (32 MPG), and σ is the standard deviation (3.5 MPG).
Calculating the z-score:
z = (34 - 32) / 3.5 = 0.57
Using a standard normal distribution table or a statistical calculator, we can find the area to the right of the z-score 0.57.
Let's assume the standard normal distribution table gives us a value of 0.2851 for z = 0.57.
Since the total area under the normal curve is 1, the probability of getting more than 34 MPG is:
P(X > 34) = 1 - P(X ≤ 34) = 1 - 0.2851 = 0.7149
Therefore, the probability that a randomly selected Cobalt gets more than 34 MPG is approximately 0.7149.
b) When selecting a sample of 10 Cobalts, the mean MPG of the sample (\(\bar{X}\)) follows a normal distribution with the same mean (32 MPG) and a standard deviation (σ) equal to the population standard deviation (3.5 MPG) divided by the square root of the sample size (√10).
σ( \(\bar{X}\) ) = σ / √n = 3.5 / √10 ≈ 1.107
We want to find the probability that the mean MPG exceeds 34 MPG for the sample of 10 Cobalts. In other words, we need to find P(\(\bar{X}\) > 34).
We can again convert the value of 34 MPG to a z-score:
z = (34 - 32) / 1.107 ≈ 1.805
Using a standard normal distribution table or a statistical calculator, we find the area to the right of the z-score 1.805.
Let's assume the standard normal distribution table gives us a value of 0.035 for z = 1.805.
Therefore, the probability that the mean MPG exceeds 34 MPG for a sample of 10 Cobalts is approximately 0.035.
c) When selecting a sample of 20 Cobalts, the mean MPG of the sample (\(\bar{X}\)) follows a normal distribution with the same mean (32 MPG) and a standard deviation (σ) equal to the population standard deviation (3.5 MPG) divided by the square root of the sample size (√20).
σ( \(\bar{X}\) ) = σ / √n = 3.5 / √20 ≈ 0.78
We want to find the probability that the mean MPG exceeds 34 MPG for the sample of 20 Cobalts. In other words, we need to find P(\(\bar{X}\) > 34).
Similarly, we can convert the value of 34 MPG to a z-score:
z = (34 - 32) / 0.78 ≈ 2.564
Using a standard normal distribution table or a statistical calculator, we find the area to the right of the z-score 2.564.
Assuming the standard normal distribution table gives us a value of 0.005 for z = 2.564.
Therefore, the probability that the mean MPG exceeds 34 MPG for a sample of 20 Cobalts is approximately 0.005.
Learn more about probability here
https://brainly.com/question/31828911
#SPJ4
Tre knows that he can mow 3 lawns in two hours. Tre starts mowing on Monday and wants to complete his 20 lawns before Friday. If he wants to work an equal amount each day, how many hours will he have to work each day to mow all 20 lawns? Explain your process.
Answers
Answer: Tre wants to mow 20 lawns in 5 days, so he needs to mow 20/5=<<20/5=4>>4 lawns per day.
If Tre can mow 3 lawns in 2 hours, then he can mow 1 lawn in 2/3=<<2/3=0.67>>0.67 hours.
This means Tre will have to work 4/0.67=<<4/0.67=6>>6 hours each day to mow all 20 lawns. Answer: \boxed{6}.
Step-by-step explanation:
the sum of three consecutive integers is 330 what is the smallest of these integers?? will give brainliest
Answers
Answer:
109
Step-by-step explanation:
Three consecutive integers:
x, x+1, x+2Sum of them:
x+(x+1)+(x+2) = 3303x + 3 = 3303x= 327x= 327/3x= 109The smallest integer out of three is 109
━━━━━━━━━━━━━━━ ♡ ━━━━━━━━━━━━━━━
3 consecutive integers = x+(x+1)+(x+2) or 3x+3 (x is the smallest number)
(Consecutive means one after another)
So 3x+3 = 330.
Now subtract 3 from both sides.
(3x-3)=3x
(330-3)=327
The left side is 3x and the right side is 327.
The equation now is 3x=327.
Now divide each side by 3 (so x is isolated)
3x÷3=x
327÷3=109
The left side is x and the right side is 109.
The final equation is x=109.
Since x is the smallest of these integers we don't have to do anything else.
Okay, so let's check the answer now. 109+110+111=330.
So the smallest of the 3 consecutive numbers is 109.
━━━━━━━━━━━━━━━ ♡ ━━━━━━━━━━━━━━━
a bin of 50 parts contains 5 that are defective. a sample of 10 parts is selected without replacement. how many samples contain at least 4 defective parts?
Answers
A bin of 50 parts contains 5 that are defective and a sample of 10 parts is selected without replacement, then total 40,753,713 samples contain at least 4 defective parts.
A bin of 50 parts contains 5 that are defective.
A sample of 10 parts is selected without replacement.
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = Samples with precisely 4 defectives + samples with precisely 5 defects
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = \(^{5}C_{4}\cdot ^{45}C_{6}+ ^{5}C_{5}\cdot^{45}C_{5}\)
Using the formula \(^nC_{r} = \frac{n!}{r!(n-r)!}\)
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = \(\frac{5!}{4!(5-4)!}\cdot\frac{45!}{6!(45-6)!}+\frac{5!}{5!(5-5)!}\cdot\frac{45!}{5!(45-5)!}\)
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = \(\frac{5!}{4!1!}\cdot\frac{45!}{6!39!}+\frac{5!}{5!0!}\cdot\frac{45!}{5!40!}\)
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = \(\frac{5\times4!}{4!\times1}\cdot\frac{45\times44\times43\times42\times41\times40\times39!}{6\times5\times4\times3\times2\times1\times39!}+1\cdot\frac{45\times44\times43\times42\times41\times40!}{5\times4\times3\times2\times1\times40!}\)
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = 5 × 15 × 44 × 43 × 7 × 41 + 1 × 9 × 11 × 7 × 41
Number of samples of size 10 from 50 pieces, at least 4 of which are faulty = 40,753,713
To learn more about sample link is here
brainly.com/question/13287171
#SPJ4
Need help with 9th-grade math. Algebra 1
A ball is thrown in the air. The path of the ball is represented by the equation h=-t^2+8t, where t represents time in seconds and h represents the height of the ball in meters.
What is the maximum height of the ball?
How long is the ball in the air for before it hits the ground?
Answers
Answer:
a) 16 meters ; b) 8 seconds
Step-by-step explanation:
The function can be represent with a parabola whose vertex is its maximum point
for answer the first question we have to find the y of the vertex
first of all we have to find the x
Vertex (x) = -b/2a = -8/-2 = 4
if we substitute t with 4, we can find the y
Vertex (y) = -(4^2) + (8*4) =
= -16 + 32 = 16
so the answer is 16 meters
for answer the second question we have to find where the parabola intercepts the x axis, that means solve the associated equation:
-t^2 + 8t = 0
t^2-8t = 0
t(t-8) = 0
t = 0
t = 8
the parabola intercept the x axis in (0,0) and in (8,0)
if we find the distance between this two points we can answer to the question
8-0 = 8 seconds
Answer:
y are you ga
Step-by-step explanation:
please help! ten points! thank you

Answers
hey could anyone help and also provide an explanation/working out? thanks a lot !

Answers
Answer:
find the volume of cone and then form the following equation
volume of cone=1/3 x base area x height
volume of cuboid= base area x height
The volume of water will be equal in both therefore u can easily form an equation.
1/3Xπ3²X10= 5X3Xh
then solve for h
h e l p :) the other side has the same 2.50 6 and 75

Answers
Answer:
the answer is 6.
g+6>75
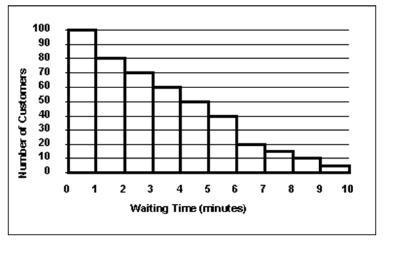
The staff of Mr. Wayne Wertz, VP of Operations at Portland Peoples Bank, prepared a frequency histogram of waiting time for walk-in customers. Approximately how many walk-in customers waited at least 6 minutes? (Note the position of the labels on the x-axis — the first column is the number of customers who waited 1 minute and the last column is the number of customers who waited 10 minutes)
Answers
The number of people who waited at least 6 minutes is given as follows:
50 people.
What is shown by the histogram?The height of each bin of the histogram represents the number of observations of the data-set in the desired interval.
The desired outcomes for this problem are given as follows:
Between 6 and 7 minutes: 20 people.Between 7 and 8 minutes: 15 people.Between 8 and 9 minutes: 10 people.Between 9 and 10 minutes: 5 people.Hence the number of people who waited at least 6 minutes is given as follows:
20 + 15 + 10 + 5 = 50 people.
More can be learned about histograms at brainly.com/question/25983327
#SPJ1
A data set includes data from student evaluations of courses. The summary statistics are n=97, x=4.18, s=0.54. Use a 0.01 significance level to test the claim that the population of student course evaluations has a mean equal to 4.25. Assume that a simple random sample has been selected. Identify the null and alternative hypotheses, test statistic, P-value, and state the final conclusion that addresses the original claim.
also, P-value
Answers
Answer:
Step-by-step explanation:
The null and alternative hypotheses are:
Null hypothesis: The population mean of student course evaluations is equal to 4.25.
Alternative hypothesis: The population mean of student course evaluations is not equal to 4.25.
The significance level is 0.01, so the test will be a two-tailed test.
The test statistic is calculated as:
t = (x - μ) / (s / √n) = (4.18 - 4.25) / (0.54 / √97) = -2.63
The degrees of freedom for the t-distribution is n-1 = 96. Using a t-table or a calculator, the P-value for a two-tailed test with 96 degrees of freedom and a t-value of -2.63 is approximately 0.010.
Since the P-value (0.010) is less than the significance level (0.01), we reject the null hypothesis. We have sufficient evidence to conclude that the population mean of student course evaluations is not equal to 4.25.
In other words, the data provides strong evidence to suggest that the average student course evaluation rating is significantly lower than 4.25.
HELP ME PLS
Given the relation below:
Write a value for that makes the relation a function
(5,9), (8, 14), (12, 18). (a, 22)
Type your answer
Answers
Answer:
A=30
Step-by-step explanation:
What is the next number in the sequence?
-2, 6, -18, 54,
Answers
Answer:162 please mark brainliest
Step-by-step explanation:2x3=6, 6x3=18, 18x3=54 so 54x3=162
the maximum weight, w, that a stepladder can hold is 250 pounds. which inequality represents this situation?
Answers
w ≤ 250
This inequality can be used to represent the maximum weight that a stepladder can hold, which is 250 pounds. In other words, the weight, w, must be less than or equal to 250 pounds.
The weight, w, must be less than or equal to 250 pounds. This inequality can be used to represent the maximum weight that a stepladder can hold, which is 250 pounds. In other words, if the weight of the object being placed on the stepladder is greater than 250 pounds, it is not safe to use the stepladder. This inequality helps to ensure the safety of the person using the stepladder, as it limits the amount of weight that can be placed upon it. Furthermore, it also helps to protect the stepladder itself, as it prevents it from being overloaded with too much weight, which could cause it to break or malfunction. In conclusion, the inequality w ≤ 250 represents the maximum weight that a stepladder can safely hold.
Learn more about inequality here
https://brainly.com/question/28823603
#SPJ4
Evaluate the line integral, where C is the given space curve. x2 + y2 + z?) ds, c: x= t, y = cos(6+), z = sin(6t), osts 21 J.(x2 1. + ) , x=, y = )ze, 36 (23++) 671 3 o X
Answers
The value of the given line integral is 8π√37. Hence, the correct option is (d) 8π√37.
The line integral of the given space curve can be evaluated as follows:
Given, the curve C is
x² + y² + z = 4.
Therefore, the equation of the curve in terms of x and y is
z = 4 - x² - y².
Let f (x, y, z) = x² + y² + z.
Hence, f (x, y, z) = x² + y² + (4 - x² - y²) = 4.
The line integral,
∫(x² + y² + z) ds, C:
x = t,
y = cos(6t),
z = sin(6t).....(1)
By formula, the line integral,
∫f (r(t)) |r'(t)| dt, a ≤ t ≤ b,
where
r(t) = (x(t), y(t), z(t))
is the parameterization of the curve and a and b are the limits of integration.
By using the given limits, the parameterization of the curve can be written as
r(t) = (t, cos(6t), sin(6t)), 0 ≤ t ≤ 2π.
Here,
x(t) = t, y(t) = cos(6t), and z(t) = sin(6t).
Therefore,
r'(t) = (1, -6 sin(6t), 6 cos(6t)).
Now,
|r'(t)| = √(1 + 36 sin²(6t) + 36 cos²(6t)) = √37.
Using the values of r(t) and |r'(t)|, the given line integral,
∫(x² + y² + z) ds can be evaluated as
∫(x² + y² + z) ds
= ∫f(r(t)) |r'(t)| dt
from a = 0 to b
= 2π∫(x² + y² + z) ds
= ∫04√37 dt
= 4√37 ∫0²πdt
= 8π√37.
The required line integral is 8π√37. Hence, the correct option is (d) 8π√37.
To know more about line integral visit:
https://brainly.com/question/30763905
#SPJ11
Help please I don’t understand

Answers
Solve for x. -3(x+n)=x

Answers
Answer:
x = 3/4 n
Step-by-step explanation:
-3(x+n)=x
Distribute
-3x-3n = x
Add 3x to each side
-3x-3n+3x= x+3x
3n = 4x
Divide by 4
3/4n = 3x/3
3/4 n = x
Add (8x - 7) + (6x + 8). simplify your answer.
Answers
Answer:
14x+1
Step-by-step explanation:
you combined like terms
8x and 6x are like terms so 8x+6x=14x
8 and (-7) are like terms so 8+(-7)=1
Answer: 14x+1
Step-by-step explanation:

what is the unit rate for You create 18 centerpieces for a party in 6 hours.
Answers
Answer: The unit rate is 3 centerpieces per hour
Step-by-step explanation:
18centterpieces/6hrs =3
help i’ll mark brainliest

Answers
Answer:
12
..... ....... ......
Help me!
Find the area of figure.

Answers
Answer:
9 cm²
Step-by-step explanation:
the area = ½× 3√2 × 3√2 = ½×18 = 9
For sheets of steel:
500 mm x 500 mm x 0.7 mm costs £6.00
1,000 mm x 1,000 mm x 0.7 mm costs £17.00
How much of a saving, in both pounds (£) and percentage (%), could you make by getting the larger sheets
cut into four pieces that are 500 mm x 500 mm?
Answers
The amount of saving in pounds is £7.00 and in percentage is 29.167%
What is percentage ?
A percentage is a figure or ratio stated as a fraction of 100 in mathematics. Although the abbreviations "pct.", "pct.", and occasionally "pc" are also used, the percent symbol, "%," is frequently used to indicate it. A % is a number without dimensions and without a standard measurement.
In essence, percentages are fractions with a 100 as the denominator. We place the percent symbol (%) next to the number to indicate that the number is a percentage. For instance, you would have received a 75% grade if you answered 75 out of 100 questions correctly on a test (75/100).
Cost of 500mm×500mm×0.7mm = £6.00
No. of sheets that can be cut will be = \(\frac{1000 * 1000 * 0.7}{500 *500 *0.7}\)
= 4 sheets
Cost of 1 sheet of 1000mm x 1,000 mm x 0.7 mm = £17.00
Cost of 4 sheets of 500 mm x 500 mm x 0.7 mm = £6.00 × £4.00
= £ 24.00
Hence saving = £ 24.00 - £17.00
= £ 7.00
Hence percentage of savings = 7/24 × 100
= 175/6
= 29.167%
To learn more about percentage from the given link
https://brainly.com/question/24877689
#SPJ1
One factor of the function f(x) = x^3 − 9x^2 + 20x − 12 is (x − 6). Describe how to find the x-intercepts and the y-intercept of the graph of f(x) without using technology. Show your work and include all intercepts in your answer.
Answers
We are given the function, \(\underline{f(x)=x^3-9x^2+20x-12}\), and are asked to find the x and y intercepts of the function.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
What is an intercept?
An intercept is where the graph of a function cross either the x or y axis. The x-intercept(s) crosses the x-axis and the y-intercept(s) crosses the y-axis.
How do find the x-intercept(s)?
To find the x-intercepts let y in your function equal zero, then solve for x.
How do find the y-intercept(s)?
To find the y-intercepts let x in your function equal zero, then solve for y.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Refer to the attached image for the rest.


Find the value of x in the solution of the system y = -4x + 48
Answers
Answer:
x = 12
Step-by-step explanation:
y= -4x+48
0=-4x+48
4x=48
x=12
The difference of a number divided by 2 and 1 is 5 find the number
Answers
Answer:
Number is 10
Step-by-step explanation:
10 divided by 2 is 5 divided by 1 is also 5
Why Eulerian path can be implemented in linear time, but not Hamiltonian path?
Answers
Eulerian path can be implemented in linear time because it follows a specific rule: a connected graph can have an Eulerian path if and only if it has either zero or two vertices of odd degree.
This means that the algorithm can quickly determine whether or not a graph has an Eulerian path by simply counting the number of odd degree vertices. This can be done in linear time, making the implementation of Eulerian path efficient and fast.
On the other hand, Hamiltonian path does not follow a specific rule, and there is no known efficient algorithm to determine whether or not a graph has a Hamiltonian path.
This means that the implementation of Hamiltonian path requires checking all possible paths in the graph, which can take a long time and is not efficient. Therefore, Hamiltonian path cannot be implemented in linear time like Eulerian path can.
To know more about Eulerian path click on below link:
https://brainly.com/question/27979322#
#SPJ11
Try another
Determine the slope of the following graph
help

Answers
Answer:
y=1/2x+3
Step-by-step explanation:
Rise/run+yintercept
1.A vegetable oil extractor costing Rs. 1,50,000 with annual operating cost of Rs. 45,000 and an estimated life of 12 years has a salvage value of Rs. 18,000. Alternate oil extractor equipment costs Rs. 54,000 with a life of 6 years has Rs. 6000 junk value and the operating costs are Rs. 75,000 annually. What is the rate of returns for the extra investment if the extractor is replaced.
Answers
To calculate the rate of return for the extra investment, we need more information such as the cash inflows from the extractor and the alternate equipment. Without this information, it is not possible to determine the rate of return.
To calculate the rate of return, we would need the cash inflows generated by both the existing extractor and the alternate equipment. Cash inflows could come from the sale of vegetable oil or any other revenue generated by using the equipment. Without these values, we cannot calculate the rate of return.
Additionally, the rate of return calculation would also require the initial investment, salvage value, and the time period considered. In this case, the initial cost and salvage value for the existing extractor are provided, but we still need the initial cost and salvage value for the alternate equipment.
Without the necessary data, it is not possible to determine the rate of return for the extra investment in the extractor replacement.
The calculation of the rate of return for the extra investment in the extractor replacement cannot be determined without knowing the cash inflows from both the existing extractor and the alternate equipment.
To k ow more about rate visit:
https://brainly.com/question/119866
#SPJ11
company a rents copiers for a monthly charge of $200 plus 10 cents per copy. company b rents copiers for a monthly charge of $400 plus 5 cents per copy. what is the number of copies above which company a's charges are the higher of the two? write your answer as a number only.
Answers
Therefore, when the number of copies made in a month is above 4000, company A's charges are higher than company B's charges in the given equation.
Let's start by setting up an equation to represent the cost of renting a copier from each company:
Cost for company A = 0.10x + 200
Cost for company B = 0.05x + 400
where x is the number of copies made in a month.
To find the number of copies above which company A's charges are higher than company B's charges, we need to set the two equations equal to each other and solve for x:
0.10x + 200 = 0.05x + 400
0.05x = 200
x = 4000
To know more about equation,
https://brainly.com/question/28243079
#SPJ11
what number of laptops would have a percentile of 90% in this sequence of numbers? 24 32 27 23 33 33 29 25 23 36 26 26 31 20 27 33 27 23 28 29 31 35 34 22 37 28 23 35 31 43
Answers
The 26th term is 36, and the 27th term is 37. Therefore, the 90th percentile is 37, meaning that 90% of the laptops have a score of 37 or lower.
what is percentile ?
A percentile is a measure used in statistics to indicate the value below which a given percentage of observations or data points in a distribution fall.
In the given question,
To find the 90th percentile in this sequence of numbers, you need to arrange them in ascending order:
20 22 23 23 23 24 25 26 26 27 27 27 28 28 29 29 31 31 31 32 33 33 33 34 35 35 36 37 43
The 90th percentile represents the value below which 90% of the data fall. To find this value, you can use the formula:
90th percentile = ((90/100) * N)th term
where N is the total number of data points in the sequence.
In this case, N = 29 (there are 29 laptops in the sequence). Substituting the values into the formula, we get:
90th percentile = ((90/100) * 29)th term
= (0.9 * 29)th term
= 26.1th term
Since we can't have a fraction of a term, we can round up to the nearest integer to get the 90th percentile. The 26th term is 36, and the 27th term is 37. Therefore, the 90th percentile is 37, meaning that 90% of the laptops have a score of 37 or lower.
To know more about percentile , visit:
https://brainly.com/question/13638390
#SPJ1